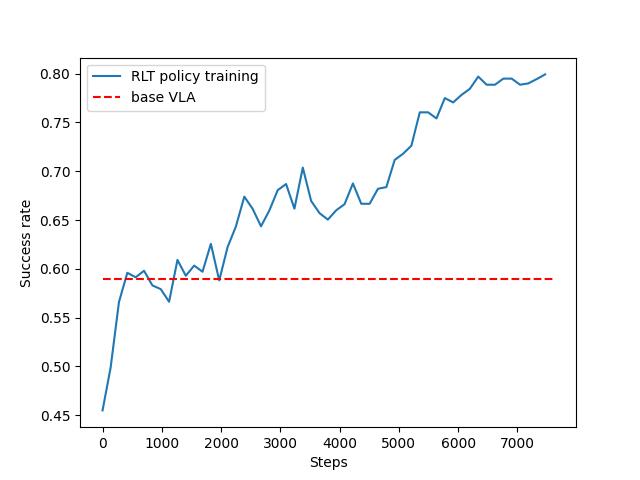
I implemented RLT to improve smolVLA (a small scale VLA) on libero. The training achieved a significant improvement of the success rate over the base poliycy.
Indeed, the success rate went from ~0.6 from the base policy to ~0.8 with RLT. However, I believe that further tuning of the hyperparameters could lead to even better results.
In particular, some of the details are not given in the original paper and I'm limited by my computational resources to explore broadly the hyperparameters.
In addition, I currently don't use expert error correction in the RLT training procedure which should greatly improve the performances especially as I would be able to correct error modes.
I plan to introduce this expert correction in the training procedure using a controller and see how it impacts the results.
The code can be found in this github repository: RLT. I will soon release a cleaner version with minimal files to reproduce the results.
I will update this page as I obtain more results and insights through my experiments.